Note
Go to the end to download the full example code
Algorithms - A real world example: QRS-Detection#
In this example we will implement a custom algorithm and discuss, when you might want to use an algorithm class over just pipelines.
Specifically we will implement a simple algorithm, designed to identify individual QRS complexes from a continuous ECG signal. If you have no idea what this all means, don’t worry about it. Simply we want to find peaks in a continuous signal that has some artifacts.
Warning
The algorithm we design is not a good algorithms! There are way better and properly evaluated algorithms to do this job! Don’t use this algorithms for anything :)
When should you use custom algorithms?#
Algorithms are a completely optional feature of tpcp and in many cases not required. However, algorithm subclasses provide a structured way to implement new algorithms when you don’t have any better structure to follow. Further they allow the setting of nested parameters (e.g. when used as parameters to pipelines) and can benefit from other tooling in tpcp (e.g. cloning). For more general information have a look at the general documentation page The fundamental components: Datasets, Algorithms, and Pipelines.
Implementing QRS-Detection#
In general our QRS-Detection will have two steps:
High-pass filter the data to remove baseline drift. We will use a Butterworth filter for that.
Apply a peak finding strategy to find the (hopefully dominant) R-peaks. We will use
find_peakswith a couple of parameters for that.
As all algorithms, our algorithm needs to inherit from tpcp.Algorithm and implement an action method.
In our case we will call the action method detect, as it makes sense based on what the algorithm does.
This detect method will first do the filtering and then the peak search, which we will split into two methods to keep
things easier to understand.
If you just want the final implementation, without all the explanation, check The final QRS detection algorithms.
Ok that is still a bunch of code… But let’s focus on the aspects that are important in general:
We inherit from
AlgorithmWe get and define all parameters in the init without modification
We define the name of out action method using
_action_method = "detect"After we do the computations, we set the results on the instance
We return self
(Optionally) we applied the
make_action_safedecorator to our action method, which makes some runtimes checks to ensure our implementation follows the tpcp spec.
import numpy as np
import pandas as pd
from scipy import signal
from tpcp import Algorithm, Parameter, make_action_safe
class QRSDetector(Algorithm):
_action_methods = "detect"
# Input Parameters
high_pass_filter_cutoff_hz: Parameter[float]
max_heart_rate_bpm: Parameter[float]
min_r_peak_height_over_baseline: Parameter[float]
# Results
r_peak_positions_: pd.Series
# Some internal constants
_HIGH_PASS_FILTER_ORDER: int = 4
def __init__(
self,
max_heart_rate_bpm: float = 200.0,
min_r_peak_height_over_baseline: float = 1.0,
high_pass_filter_cutoff_hz: float = 0.5,
):
self.max_heart_rate_bpm = max_heart_rate_bpm
self.min_r_peak_height_over_baseline = min_r_peak_height_over_baseline
self.high_pass_filter_cutoff_hz = high_pass_filter_cutoff_hz
@make_action_safe
def detect(self, single_channel_ecg: pd.Series, sampling_rate_hz: float):
ecg = single_channel_ecg.to_numpy().flatten()
filtered_signal = self._filter(ecg, sampling_rate_hz)
peak_positions = self._search_strategy(
filtered_signal, sampling_rate_hz
)
self.r_peak_positions_ = pd.Series(peak_positions)
return self
def _search_strategy(
self,
filtered_signal: np.ndarray,
sampling_rate_hz: float,
use_height: bool = True,
) -> np.ndarray:
# Calculate the minimal distance based on the expected heart rate
min_distance_between_peaks = (
1 / (self.max_heart_rate_bpm / 60) * sampling_rate_hz
)
height = None
if use_height:
height = self.min_r_peak_height_over_baseline
peaks, _ = signal.find_peaks(
filtered_signal, distance=min_distance_between_peaks, height=height
)
return peaks
def _filter(
self, ecg_signal: np.ndarray, sampling_rate_hz: float
) -> np.ndarray:
sos = signal.butter(
btype="high",
N=self._HIGH_PASS_FILTER_ORDER,
Wn=self.high_pass_filter_cutoff_hz,
output="sos",
fs=sampling_rate_hz,
)
return signal.sosfiltfilt(sos, ecg_signal)
Testing the implementation#
To test the implementation, we load our example ECG data using the dataset created in a previous example.
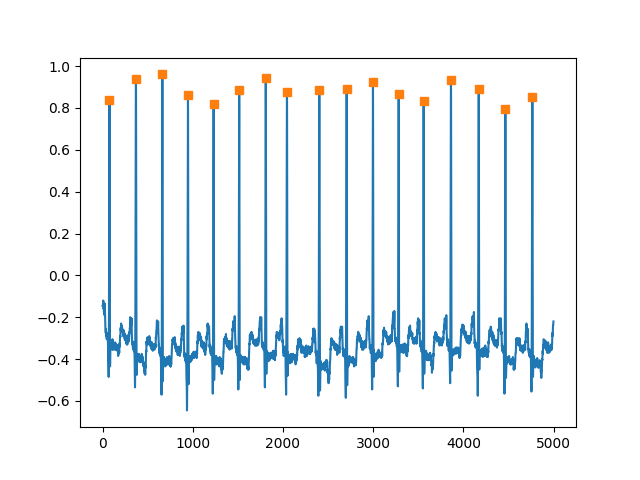
Based on the simple test we can see that our algorithm works (at least for this piece of data).
from pathlib import Path
from examples.datasets.datasets_final_ecg import ECGExampleData
# Loading the data
try:
HERE = Path(__file__).parent
except NameError:
HERE = Path().resolve()
data_path = HERE.parent.parent / "example_data/ecg_mit_bih_arrhythmia/data"
example_data = ECGExampleData(data_path)
ecg_data = example_data[0].data["ecg"]
# Initialize the algorithm
algorithm = QRSDetector()
algorithm = algorithm.detect(ecg_data, example_data.sampling_rate_hz)
# Visualize the results
import matplotlib.pyplot as plt
plt.figure()
plt.plot(ecg_data[:5000])
subset_peaks = algorithm.r_peak_positions_[algorithm.r_peak_positions_ < 5000.0]
plt.plot(subset_peaks, ecg_data[subset_peaks], "s")
plt.show()
Making the algorithm trainable#
The implementation so far heavily depends on the value of the min_r_peak_height_over_baseline parameter.
If this is set incorrectly, everything will go wrong.
This parameter describes the minimal expected value of the filtered signal at the position of an R-peak.
Without looking at the filtered data, this value is hard to guess.
The value will depend on potential preprocessing applied to the data and the measurement conditions.
But we should be able to calculate a suitable value based on some training data (with R-peak annotations) recorded
under similar conditions.
Therefore, we will create a second implementation of our algorithm that is trainable.
Meaning, we will implement a method (self_optimize) that is able to estimate a suitable value for our cutoff
based on some training data.
Note, that we do not provide a generic base class for optimizable algorithms.
If you need one, create your own class with a call signature for self_optimize that makes sense for the group of
algorithms you are trying to implement.
From an implementation perspective, this means that we need to do the following things:
Implement a
self_optimizemethod that takes the data of multiple recordings including the reference labels to calculate a suitable threshold. This method should modify only parameters marked asOptimizableParameterand then returnself.We need to mark the parameters that we want to optimize as
OptimizableParameterusing the type annotations on the class level.We introduce a new parameter called
r_peak_match_tolerance_sthat is used by ourself_optimizemethod. Changing it, changes the output of our optimization. Therefore, it is a Hyper-Parameter of our method. We mark it as such using the type-hints on class level.(Optional) Wrap the
self_optimizemethod with themake_optimize_safedecorator. It will perform some runtime checks and inform us, if we did not implementself_optimizeas expected.
Note
The process required to implement an optimizable algorithm will always be very similar to what we did here. It doesn’t matter, if the optimization only optimizes a threshold or trains a neuronal network. The structure will be very similar.
From a scientific perspective, we optimize our parameter by trying to find all R-peaks without a height restriction
first.
Based on the detected R-peaks, we determine, which of them are actually correctly detected, by checking if they are
within the threshold r_peak_match_tolerance_s of a reference R-peak.
Then we find the best height threshold to maximise our predictive power within these preliminary detected peaks.
Again, there are probably better ways to do it… But this is just an example, and we already have way too much code that is not relevant for you to understand the basics of Algorithms.
from sklearn.metrics import roc_curve
from tpcp import HyperParameter, OptimizableParameter, make_optimize_safe
from examples.algorithms.algorithms_qrs_detection_final import (
match_events_with_reference,
)
class OptimizableQrsDetector(QRSDetector):
min_r_peak_height_over_baseline: OptimizableParameter[float]
r_peak_match_tolerance_s: HyperParameter[float]
def __init__(
self,
max_heart_rate_bpm: float = 200.0,
min_r_peak_height_over_baseline: float = 1.0,
r_peak_match_tolerance_s: float = 0.01,
high_pass_filter_cutoff_hz: float = 1,
):
self.r_peak_match_tolerance_s = r_peak_match_tolerance_s
super().__init__(
max_heart_rate_bpm=max_heart_rate_bpm,
min_r_peak_height_over_baseline=min_r_peak_height_over_baseline,
high_pass_filter_cutoff_hz=high_pass_filter_cutoff_hz,
)
@make_optimize_safe
def self_optimize(
self,
ecg_data: list[pd.Series],
r_peaks: list[pd.Series],
sampling_rate_hz: float,
):
all_labels = []
all_peak_heights = []
for d, p in zip(ecg_data, r_peaks):
filtered = self._filter(d.to_numpy().flatten(), sampling_rate_hz)
# Find all potential peaks without the height threshold
potential_peaks = self._search_strategy(
filtered, sampling_rate_hz, use_height=False
)
# Determine the label for each peak, by matching them with our ground truth
labels = np.zeros(potential_peaks.shape)
matches = match_events_with_reference(
events=potential_peaks,
reference=p.to_numpy().astype(int),
tolerance=self.r_peak_match_tolerance_s * sampling_rate_hz,
)
tp_matches = matches[(~np.isnan(matches)).all(axis=1), 0].astype(
int
)
labels[tp_matches] = 1
labels = labels.astype(bool)
all_labels.append(labels)
all_peak_heights.append(filtered[potential_peaks])
all_labels = np.hstack(all_labels)
all_peak_heights = np.hstack(all_peak_heights)
# We "brute-force" a good cutoff by testing a bunch of thresholds and then calculating the Youden Index for
# each.
fpr, tpr, thresholds = roc_curve(all_labels, all_peak_heights)
youden_index = tpr - fpr
# The best Youden index gives us a balance between sensitivity and specificity.
self.min_r_peak_height_over_baseline = thresholds[
np.argmax(youden_index)
]
return self
Testing the implementation#
To test the trainable implementation, we need a train and a test set. In this case we simply use the first two recordings as train set and a third recording as test set.
Then we first call self_optimize with the train data.
train_data = example_data[:2]
train_ecg_data = [d.data["ecg"] for d in train_data]
train_r_peaks = [d.r_peak_positions_["r_peak_position"] for d in train_data]
algorithm = OptimizableQrsDetector()
algorithm = algorithm.self_optimize(
train_ecg_data, train_r_peaks, train_data.sampling_rate_hz
)
After the optimization, we can access the modified parameters.
print(
"The optimized value of the threshold `min_r_peak_height_over_baseline` is:",
algorithm.min_r_peak_height_over_baseline,
)
The optimized value of the threshold `min_r_peak_height_over_baseline` is: 0.5434583752370183
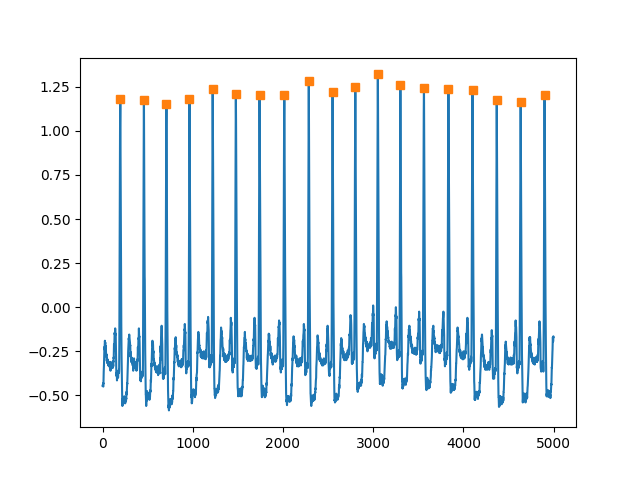
Then we can apply the algorithm to our test set. And again, we can see that the algorithm works fine on the piece of data we are inspecting here.
test_data = example_data[3]
test_ecg_data = test_data.data["ecg"]
algorithm = algorithm.detect(test_ecg_data, test_data.sampling_rate_hz)
# Visualize the results
plt.figure()
plt.plot(test_ecg_data[:5000])
subset_peaks = algorithm.r_peak_positions_[algorithm.r_peak_positions_ < 5000.0]
plt.plot(subset_peaks, test_ecg_data[subset_peaks], "s")
plt.show()
Total running time of the script: (0 minutes 1.434 seconds)
Estimated memory usage: 31 MB